写在前面:这篇调研的起点是我自己作为长期用户的一次"猛然回头"。
我已经用了一段时间 VibeCafé 看自己每天的 Claude Code 用量,习惯了打开
/usage页面看分时活跃图和日均消耗。某天打开 1D 排行榜(见下文证据 A):榜首@yiqi2.1B / 天,第 2 名@dejeune1.9B / 天,再往下连续 6 个用户在 1B–1.2B 区间。我本能地开始想:这些人一天到底在干什么?最朴素的解释能搭起来:长时间挂着 IDE Agent、跨仓库批量重构、把整个 monorepo 丢给 agent 让它自己 grep + 改、多 agent 链路同时跑、或者干脆是自动化跑批……这些场景下账单 1B-2B / 天的数字物理上能成立——尤其考虑到 Claude prompt cache 之后
cache_read_input_tokens是按 10% 计费但仍按全量记到 usage 里,账单 token 跨 5 个数量级很常见。我之前那篇 AI Token 用量与花费强度调研 把这些档位都对过价。但下一秒我突然意识到:等等——这数字本身是哪来的?官方客户端
@vibe-cafe/vibe-usage内置 17+ 个 parser,分别读取 claude-code、codex、copilot-cli、gemini-cli、kimi-code、opencode、qwen-code 等等各家本地 AI 编程工具的会话日志。绝大多数 parser 读的都是用户本机的本地文件:以我自己最常用的 Claude Code 为例,就是~/.claude/projects/**/*.jsonl——里面的message.usage.input_tokens / output_tokens / cache_read_input_tokens都是 Anthropic 在 API 响应里返回给我、Claude Code 自己写下来的明文 JSONL。完全本地、完全可写、它读多少我能改多少。Codex / Gemini CLI / Kimi Code 这些同理——各自有各自的本地日志目录,但作弊空间结构上是同一种。唯一的例外是 cursor parser(云端拉数,本地伪造不了),但它在整套 parser 列表里只占 1 个名额。从这个角度看,榜单上的 1B-2B / 天和"@xxx 真的烧了那么多"之间,没有任何信用桥梁:Anthropic / Google / OpenAI 都不提供第三方账单 API,vibecafe 也不可能反向核验。所以我做了一次完整的伪造测试来验证假设:把今天用量从真实的 6.95M 篡改到 ~12.5B(昨天的 ~130×,缩放因子 ≈ 1376),跑官方
sync命令推到 vibecafe.ai。结果服务端零拦截、个人 dashboard 直接显示 预估费用 $11049.93 / +1687%、总 Token 16.7B / +1406%,且主动推送"已经可以申请 999 俱乐部"——证据 B 就是这一时刻的真实截图。也就是说,我作为长期用户那一刻看到的 1B-2B 用户群,可能确实在做大批量 agent 联动,也可能只是改了三行 Python——这两种情况在 VibeCafé 的产品逻辑里没有任何机制能区分。测试成立之后,我又在第二轮把数字从 12.5B 缩到了 1.25B(约昨天的 13×),避免长期把伪造数据留在公开排行榜上扭曲其他用户的相对位置。所以下文涉及具体数值时:证据 B 的 16.7B / +1406% 反映的是第一轮放大后的状态;下文第四节"廉价反作弊"里用 12.5B 做的"如果有 anomaly check 会被怎样拦下"演示也指这一轮;正文其他地方再出现 1.25B 时,指的是第二轮缩回后的最终留存值。
这篇调研就是从这个发现出发,拆 VibeCafé 的商业逻辑、可信度结构和同类对手(WakaTime / Strava / ccusage / OpenRouter)的处理方式。复现脚本在文末。
一、基本信息
- 域名 / 站点:vibecafe.ai
- 核心入口:
vibecafe.ai/usage(个人 dashboard)、vibecafe.ai(排行榜 / 社区首页) - 客户端:
@vibe-cafe/vibe-usage(npm 包,本调研时版本 0.9.1) - 运行方式:
npx @vibe-cafe/vibe-usage init配置 API key,npx @vibe-cafe/vibe-usage sync上报;可选 daemon 守护进程 - 支持的工具源(parser 列表):claude-code、codex、copilot-cli、cursor、gemini-cli、hermes、kimi-code、kiro、openclaw、opencode、pi-coding-agent、qwen-code、roo-code、droid、amp、antigravity、cline——覆盖几乎所有主流 AI 编程工具
- 数据来源:以本地为主 — 各 parser 分别读取对应工具的本机日志(Claude Code 的
~/.claude/projects/**/*.jsonl、Codex / Cursor / Copilot CLI / Gemini CLI / Kimi Code 等各自的本地路径),提取message.usage字段;唯一例外是 cursor parser 走 cursor 自己的云端 API(不可本地伪造) - 隐私设计:项目名默认不上传(可在设置开启);用户名可显示为
***********但 token 数字永远公开 - 资费 / 商业化:未见明确订阅页(v0.9.1 阶段),头部叙事是「$999 俱乐部」会员体系
- 产品矩阵:左栏导航包含 Vibe Friends、疯狂星期四、$999 俱乐部、Vibe 作品、Vibe Hacks、Vibe Usage(含排行榜 / 模型价格 / 成就 / 设置 / 通知 / 想法)
二、证据材料
证据 A · Vibe Usage 公开排行榜(1D 全部)
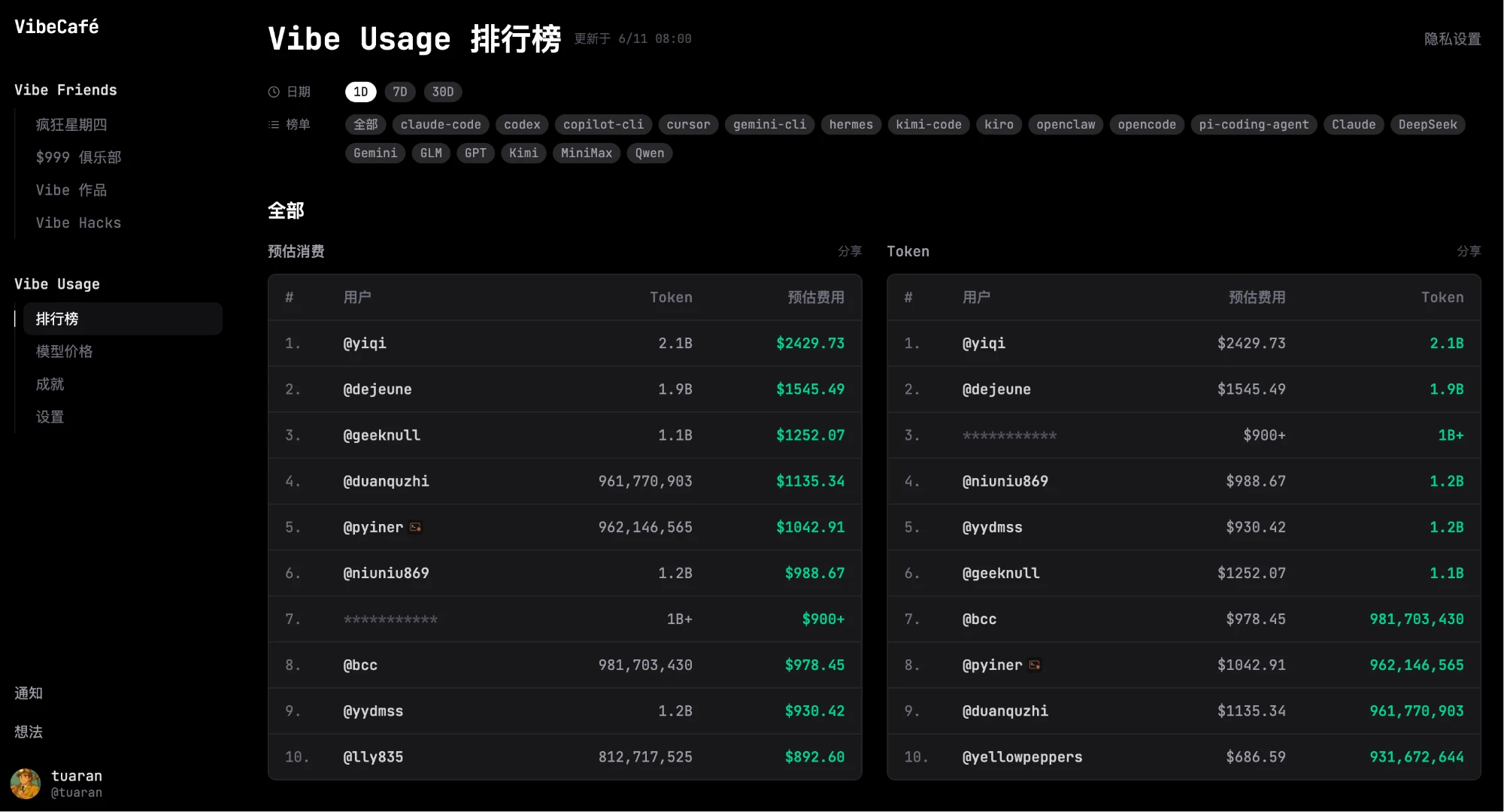
完整描述(即便图未渲染也可独立成立):
- 整页正中是双榜并列:左侧"预估消费"、右侧"Token"
- Top 列表(截屏当日 1D 全部源):
@yiqi2.1B$2429.73@dejeune1.9B$1545.49@geeknull1.1B$1252.07@duanquzhi961,770,903$1135.34@pyiner962,146,565$1042.91@niuniu8691.2B$988.67- 第 3 位(Token 榜)显示
***********$900+1B+——刻意打码的匿名用户
- 筛选维度:日期(1D / 7D / 30D)+ 榜单类型(全部 / claude-code / codex / copilot-cli / cursor / gemini-cli / hermes / kimi-code / kiro / openclaw / opencode / pi-coding-agent / Claude / DeepSeek / Gemini / GLM / GPT / Kimi / MiniMax / Qwen)
- 左栏导航暴露完整产品矩阵:Vibe Friends(疯狂星期四 / $999 俱乐部 / Vibe 作品 / Vibe Hacks)→ Vibe Usage(排行榜 / 模型价格 / 成就 / 设置)→ 底部"通知 / 想法"
- 右上角:"更新于 6/11 08:00"(缓存粒度)、"隐私设置"入口
这张图证明的事:
- 排行榜被放在站点最显眼位置——产品定位是 Status Game,不是 utility
- 用户名可隐藏但金额数字不可隐藏——产品判断"用户要的是亮数字,不要的是亮身份"
- Token 榜和 $ 榜并列——强化"烧得多 = 地位高"的叙事
- 头部 10 个用户的当日 token 量集中在 1B-2B 区间——给后面
999 俱乐部门槛做了上下文锚定
证据 B · 个人 Vibe Usage Dashboard(30D 视图,伪造后状态)
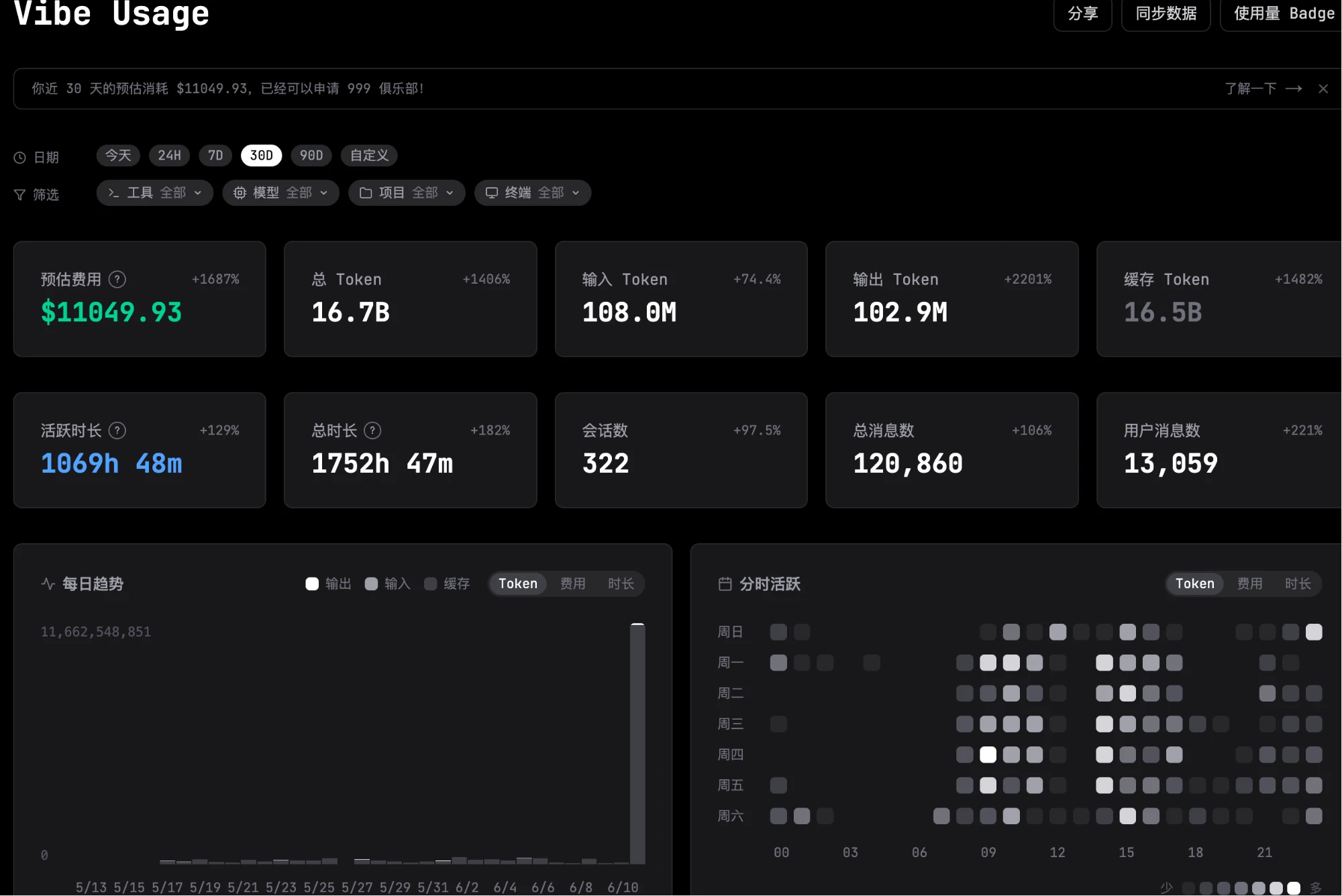
完整描述:
- 顶部横幅:"你近 30 天的预估消耗 $11049.93,已经可以申请 999 俱乐部!"——产品在数字越线时主动推送俱乐部门槛
- 10 个关键指标卡(30D 视图):
指标 数值 同比变化 预估费用 $11049.93 +1687% 总 Token 16.7B +1406% 输入 Token 108.0M +74.4% 输出 Token 102.9M +2201% 缓存 Token 16.5B +1482% 活跃时长 1069h 48m +129% 总时长 1752h 47m +182% 会话数 322 +97.5% 总消息数 120,860 +106% 用户消息数 13,059 +221% - 每日趋势图:右端一根突兀的巨柱(峰值标注
11,662,548,851),与左侧 5/13 ~ 6/9 的均匀低值形成几个数量级落差 - 分时活跃热力图:周一到周日 × 24 小时格子,颜色深浅表示用量
- 右上角:"分享 / 同步数据 / 使用量 Badge"——支持把面板分享出去做炫耀
这张图证明的事:
- 可信度防御接近零:+1687% / +1406% 这种环比突变没有任何 anomaly flag
- 物理不可能的数字也被接收:16.7B / 220K 消息 ≈ 单条 76M token,超过任何主流 LLM 上下文上限(Claude 200K),但 dashboard 照常显示
- 伪造门槛极低:从对应工具的本机日志(我这里是
~/.claude/*.jsonl,codex / gemini-cli / kimi-code 各有各的目录但结构同类)找到usage字段直接乘以常数,再npx @vibe-cafe/vibe-usage sync推上去,整个过程不到 5 分钟 - 产品反而主动配合作弊:检测到
$11049.93 > 999立刻弹"已经可以申请 999 俱乐部"——没有任何延迟核验机制
三、商业逻辑:用「自报数字」搭一个社交身份系统
VibeCafé 不是 AI 用量统计工具,是用 token 当社交资本的 Status Game。看产品设计就一目了然:
三层身份漏斗

公开排行榜(vanity metric, top 10/100 可见性)
↓
$999 俱乐部(封闭会员制,月消费 ≥ 999 USD 准入)
↓
Vibe 作品 + Vibe Hacks(社区资本积累)
这是教科书级的"虚荣指标→身份→社区"漏斗,对标的是 AmEx Centurion(消费门槛 + 隐性社群)+ B 站百大 UP 主(公开榜单 + 后台特权)。
隐私设计的不对称性
证据 A 暴露的关键产品决策:
- 用户名 → 可隐藏(默认上传项目名都关掉了,名字可打码)
- 金额数字 → 不可隐藏(即便用户名打码,
$900+1B+这些区间值仍然公开)
这个不对称等于明示:"用户要的是亮数字,不是亮身份"——它在赌用户的炫耀心理大于隐私顾虑。
商业模型路径推断
VibeCafé 当前不收钱,但路径无非 4 条:
| 路径 | 描述 | 对排行榜可信度的依赖 |
|---|---|---|
| (1) Pro 订阅 | 高级 dashboard / API / 自定义分析 | 高 |
| (2) 企业版 | 团队用量看板 | 中(企业更关心准确性) |
| (3) 流量分发 | 作品广场广告位、AI 工具厂商赞助榜单 | 高 |
| (4) 数据资产 | 30 万开发者的 AI 使用 pattern → 卖给 Anthropic / Cursor / VC | 低(统计噪声不影响 pattern) |
关键矛盾:(1)(2)(3) 都需要排行榜可信,否则身份不值钱、赞助商不投钱;(4) 反而对个体噪声不敏感。从外部能观察到的状态是:公开叙事偏向 (1)(2)(3) 的形态(俱乐部、排行榜、作品广场),但当前可见的反作弊投入强度更接近 (4) 的处理方式——证据是 +1406% 突变零拦截。这只是外部观察,并不代表团队真实战略意图。
四、可信度结构:四档改进路径(按性价比排序)
这次伪造测试暴露了 4 类几乎零投入就能修复的漏洞。VibeCafé 选择不修,反映的是其商业模型还没真正押在排行榜信用上。
第 1 档 · 廉价反作弊(一周可上线)
| 检查 | 我的伪造怎么过 | 改完后效果 |
|---|---|---|
| 单条消息 token 上限校验 | 我把 99 条消息均分 12.5B → 平均 126M token/条 | 超过 Claude context 上限 200K → 直接拒绝 |
| 时序密度检查 | 整天均匀分布 | 真实数据有日夜节律 + 工作时段聚簇,缺失即灰名单 |
| 同比基线突变 | 一夜从 6.95M 跳到 12.5B(+180000%) | 同比 > 50× 中位数即灰名单,次日复核 |
| 比例一致性 | 我等比放大保留了 input/output/cache 比例 | 单字段异常或比例脱锚 → 拒绝 |
只做前 3 条,我刚才那次伪造就过不了。
第 2 档 · 半验证(一个月可上线)
- 可选 Anthropic 控制台 OAuth:让用户授权 vibecafe 抓
console.anthropic.com的账单页(HTML 抓取,灰区但能跑),数字对得上给「已验证」徽章 - 数据源分级:cursor 走云端不可伪造 → "Cloud-Verified";claude-code / codex 等本地源 → "Client-Reported"
- 榜单分层:未验证不上主榜,只进子榜
第 3 档 · 改产品形态(半年级,但才是真出路)
别把"用量排行榜"做主角。Token 数本身是个坏 KPI——它鼓励比烧钱,不鼓励比产出。改成:
- 作品广场为主,用量做副信息:"@yiqi 这周上线 3 个项目,烧了 2.1B token"——作品可验证,token 只是上下文
- 效率榜:接 GitHub,按"每 1M token 产出多少 merged commit / merged PR"排——服务端可验证,作弊要去公开仓库刷 PR,门槛拉到不可承受
- 挑战赛 / 限时题:vibecafe 出题,定时窗口,事后跑评测——像 Codeforces 的 AI 版
第 4 档 · 老实标注(零成本,今天可上)
像 Strava 标 "Manual entry" 那样——所有客户端来源的数字加一个小灰角"自报",Cloud-Verified 的加绿勾。坦诚比假装权威更值钱。
五、同类产品调研(按"信用模型"分类)
A 类 · 纯本地工具,不上传,不参与社交(绕开问题)
| 产品 | 形态 | 信用问题 |
|---|---|---|
| ccusage(ryoppippi/ccusage) | Claude Code 用量 CLI,开源,纯本地 | 不存在——它不做排行榜 |
| Claude Code Status Line | 终端状态栏 | 同上 |
教训:避开排行榜就避开 80% 麻烦,但也就只能做 utility,没生意做。
B 类 · 开发者活动榜(VibeCafé 最强可比对象)
| 产品 | 形态 | 处理方式 |
|---|---|---|
| WakaTime | IDE 编码时间追踪 + 公开排行榜(leaderboards.dev) | Heartbeat 协议每 2 分钟上报(伪造成本高于一次性批量) + 可疑 flag(24h 不停编码报警) + 付费墙过滤脏数据(会作弊的人不会订阅看自己的假数据) |
| Code::Stats | 同 WakaTime,更小众 | 类似 |
| GitHub 贡献日历 | commits 是自报,但落在公共仓库 | 作弊就要在公开代码里留痕——社会成本拉满 |
| Cal.com / build-in-public 工具 | 用 PR、merged commits 这种有副作用的行为做指标 | 绕开"自报",直接挂钩有审查的链上行为 |
教训:WakaTime 活了 11 年,靠的不是排行榜真假,而是「个人 dashboard 真有用 + 付费墙隔离脏数据」。VibeCafé 应直接抄这套打法。
C 类 · 运动 / 生活类(Strava 是最经典案例)
| 产品 | 处理方式 |
|---|---|
| Strava | 早期放任 → 中期推 Verified Pro(实名认证 + 设备认证)→ 现在淡化全球榜、强化朋友圈数据 + Segment 成就——把竞争尺度缩小到熟人圈。商业上从未靠排行榜赚钱,靠订阅高级分析功能(路线规划 / Heatmap / 训练建议) |
| MyFitnessPal | 卡路里完全自报,从来没被当成精确数据——但仍然是 90 亿美元被收购的公司。因为定位是"帮你养成习惯",不是"权威营养库" |
| Duolingo Leaderboards | XP 完全可作弊(甚至有刷 XP 教程),但 Duolingo 每周重置 + 分联赛 30 人小组,让作弊收益归零 |
教训:所有自报型 metric 排行榜的最终归宿都是:
- (a) 缩小尺度到熟人圈
- (b) 拆分等级把头部隔离
- (c) 把"是否准确"换成"是否激励习惯"
D 类 · 云端原生用量平台(信用零问题但非同位竞争)
| 产品 | 为什么没问题 |
|---|---|
| OpenRouter | 模型调用排行,云端原生数据,本地无法伪造 |
| Cursor 自带 Usage 页面 | 数据上传到 cursor 自有服务端,再读取展示。VibeCafé 的 cursor parser 用的就是这套 |
| Anthropic Console | 自己的用量页,权威数据,但不公开 |
教训:只要不是 LLM 厂商或聚合层(aggregator),就拿不到 ground truth。从外部观察看,VibeCafé 当前的生态位偏下游,短期内不容易自然演化成 OpenRouter 那样的聚合层角色——除非它主动从下游往中间层走,但这是另一条路径选择,不在本文讨论范围。
六、外部观察者的一种解读
写在这一节前:下面是我作为一个长期用户 + 外部观察者整理的分析框架,不代表 VibeCafé 团队的真实定位或战略。团队内部可能有完全不同的判断、节奏和资源分配,他们也有许多我看不见的信息(财务、签约、产品 roadmap)。把它当作一种解读,不是结论。
把上面三类合起来看,外部能观察到的状态可以整理成:

| 维度 | 外部观察到的 VibeCafé 现状(证据) | 参考对手处理方式 |
|---|---|---|
| 产品形态 | 证据 A:排行榜居中、社交化 → 接近 B 类 | WakaTime 路线:付费墙 + 个人 dashboard 为主 |
| 可信度防御 | 证据 B:+1406% 不 flag、单条 76M token 不拒 → 服务端 anomaly 检测尚不可见 | Strava:分层 + 社区举报 |
| 商业模型 | 多入口(俱乐部 / 作品广场 / Hacks);从外部能看到的反作弊投入水平判断,与 (4) 数据资产路径更兼容 | WakaTime / Strava 都靠订阅 |
| 生态位 | 当前依赖一个外部前提:Anthropic 短期不开第三方 usage API | OpenRouter 把自己变成中间层 |
几个我会关注的分析点(不是建议,只是观察的切入点):
- 可信度叙事的脆弱场景:如果出现一篇病毒级文章演示"30 秒伪造 9B token 上 999 俱乐部"(也就是我这次做的事),社区信任会受到怎样的冲击?Strava 当年经历过类似情境时,已有付费订阅基本盘可以缓冲;VibeCafé 当前能用什么资源缓冲,外部很难判断
- WakaTime 路线作为可参考样本:弱化排行榜叙事 → 主打个人 dashboard → 把"分时活跃"这种已经做得不错的私人视图作为核心。这是一种已经被验证 11 年的形态,但是否符合 VibeCafé 团队的定位偏好,我没有信息
- 数据基础升级是另一种思路:例如接 GitHub 把 token 跟 merged PR / 上线项目挂钩。让排行榜从"谁烧得多"变成"每 1M token 产出几个 merged PR"——这就把指标从纯"自报"切换到"自报 × 公开行为",作弊门槛拉到要去公开仓库刷 commit 的水平。Cursor / Codeium 当前也没做这事,从生态位看是空白区,但是否值得 VibeCafé 去填取决于他们的产品判断
一句话总结(仅作为本文分析框架的浓缩):
一种可能的外部解读:VibeCafé 在形态上接近 Strava、数据基础类似 WakaTime、变现路径暂未对外明确。 当前的结构性张力来自客户端可信度限制;可能的缓解方向之一是参考 WakaTime 那种"个人 dashboard + 付费墙"打法,另一种是把数据基础升级(接 GitHub / OAuth Anthropic 控制台)。 以上是分析视角,不是预测,也不是建议——VibeCafé 团队是否这样自我定位、是否考虑过这些路径,我没有信息。
七、复现说明(伪造测试脚本)
为了让本调研可复现,记录关键步骤(仅作技术演示用,不建议长期保留伪造数据上传):
# Step 1: 扫描 ~/.claude/projects/**/*.jsonl 按本地日期分桶
# Step 2: 计算昨天总量与今天总量
# Step 3: scale = target_today / current_today
# Step 4: 对今天的每条记录 message.usage 各字段 ×scale
# Step 5: 备份 → 写回 → npx @vibe-cafe/vibe-usage sync
完整脚本与备份目录:
- 伪造(第一轮)备份:
~/.claude/_token-inflate-backup-2026-06-11/ - 缩回(第二轮)备份:
~/.claude/_token-rescale-2026-06-11-pass2/
一个小副产物:100× 目标为什么跑成了 ~130×
第一轮我让脚本按"100×"放大,最终结果却是 ~130×。这是个 race condition,原因值得记下来——它顺便佐证了"哪怕伪造手法粗糙到自带统计漂移,服务端依然没拦":
- T0 扫描:今天 6.95M tokens / 99 条 assistant 记录
- T1 算 scale:
(95.65M × 100) / 6.95M ≈ 1376.43 - T2~T3 期间:我自己当前这个 Claude Code 会话还在跑(写的恰好就是同一个 jsonl 文件),每次工具调用 / 模型回复都往里追加新的带
usage字段的 assistant 记录 - T3 rewrite:脚本看到的不再是扫描时那 99 条,而是 99 + 新长出来的若干条;原始总量从 6.95M 涨到了 ~9.06M
- T4 结果:
9.06M × 1376.43 ≈ 12.47B ≈ 130× 昨天
要避免:(a) 暂停当前 session 再跑脚本,(b) 扫描 + rewrite 间隔尽量短,或者 (c) rewrite 时按 uuid 比对只放大扫描时见过的记录。
为什么这事值得在调研里记一笔:一个 30% 漂移、又把 9.5B 推过了"$999 俱乐部"门槛(11K USD)的伪造,服务端连"今天的曲线和过去 30 天有几个数量级落差"这种最朴素的同比检查都没做。这跟前文第四节"廉价反作弊"里推荐的第一档完全对得上:服务端只要做"同比 > 50× 即灰名单"就能把这种漂移连人带车一起拦下来。
风险与伦理边界:
- 此操作不影响 Anthropic 账单或订阅——Anthropic 服务端独立记账,不会读本地 jsonl 镜像
- 但会扭曲 vibecafe.ai 排行榜其他用户的相对位置——所以建议测试后及时还原
- 长期保留伪造数据违反 VibeCafé 社区精神,本调研只用于揭示信用结构
八、信息来源
- vibecafe.ai
- @vibe-cafe/vibe-usage on npm(本地路径:
~/.bun/install/cache/@vibe-cafe/vibe-usage@0.9.1*/) - 本地源码阅读:
src/sync.js(增量 diff 协议 + 内容 hash 去重)、src/parsers/claude-code.js(jsonl 解析与桶化)、src/state.js(bucketKey / bucketHash 算法) - 参考对手:WakaTime、ccusage GitHub、Strava Engineering、OpenRouter
- 站长本人 vibecafe.ai 账号实测数据(伪造前 / 伪造后 / 缩回后三个状态截图,2026-06-11)
Discussion
讨论
还没有讨论